OpenAI, the artificial intelligence (AI) research company behind ChatGPT and the DALL-E 2 art generator, has unveiled the highly anticipated GPT-4 model. Excitingly, the company also made it immediately available to the public through a paid service.
GPT-4 is a large language model (LLM), a neural network trained on massive amounts of data to understand and generate text. It’s the successor to GPT-3.5, the model behind ChatGPT.
The GPT-4 model introduces a range of enhancements over its predecessors. These include more creativity, more advanced reasoning, stronger performance across multiple languages, the ability to accept visual input, and the capacity to handle significantly more text.
More powerful than the wildly popular ChatGPT, GPT-4 is bound to inspire an in-depth exploration of its capabilities and further accelerate the adoption of generative AI.
Improved capabilities
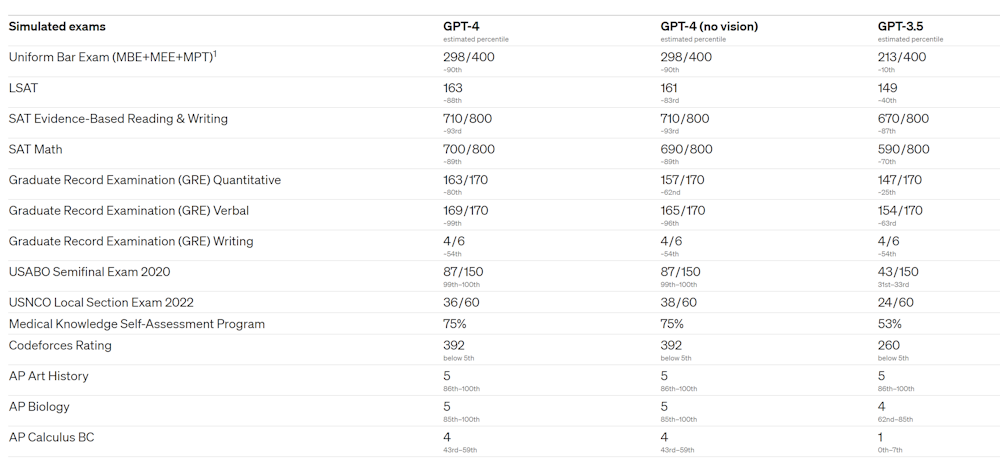
Among many results highlighted by OpenAI, what immediately stands out is GPT-4’s performance on a range of standardised tests. For example, GPT-4 scores among the top 10% in a simulated US bar exam, whereas GPT-3.5 scores in the bottom 10%.

This table from the OpenAI technical report shows the performance of the model on a range of simulated standardised tests. GPT-4 often performs in the top 20% range.
OpenAI
GPT-4 also outperforms GPT-3.5 on a range of writing, reasoning and coding tasks. The following examples illustrate how GPT-4 displays more reliable commonsense reasoning than GPT-3.5.
Read more